This module is an alpha integration and still work in progress!!
GCP Architecture and Setup
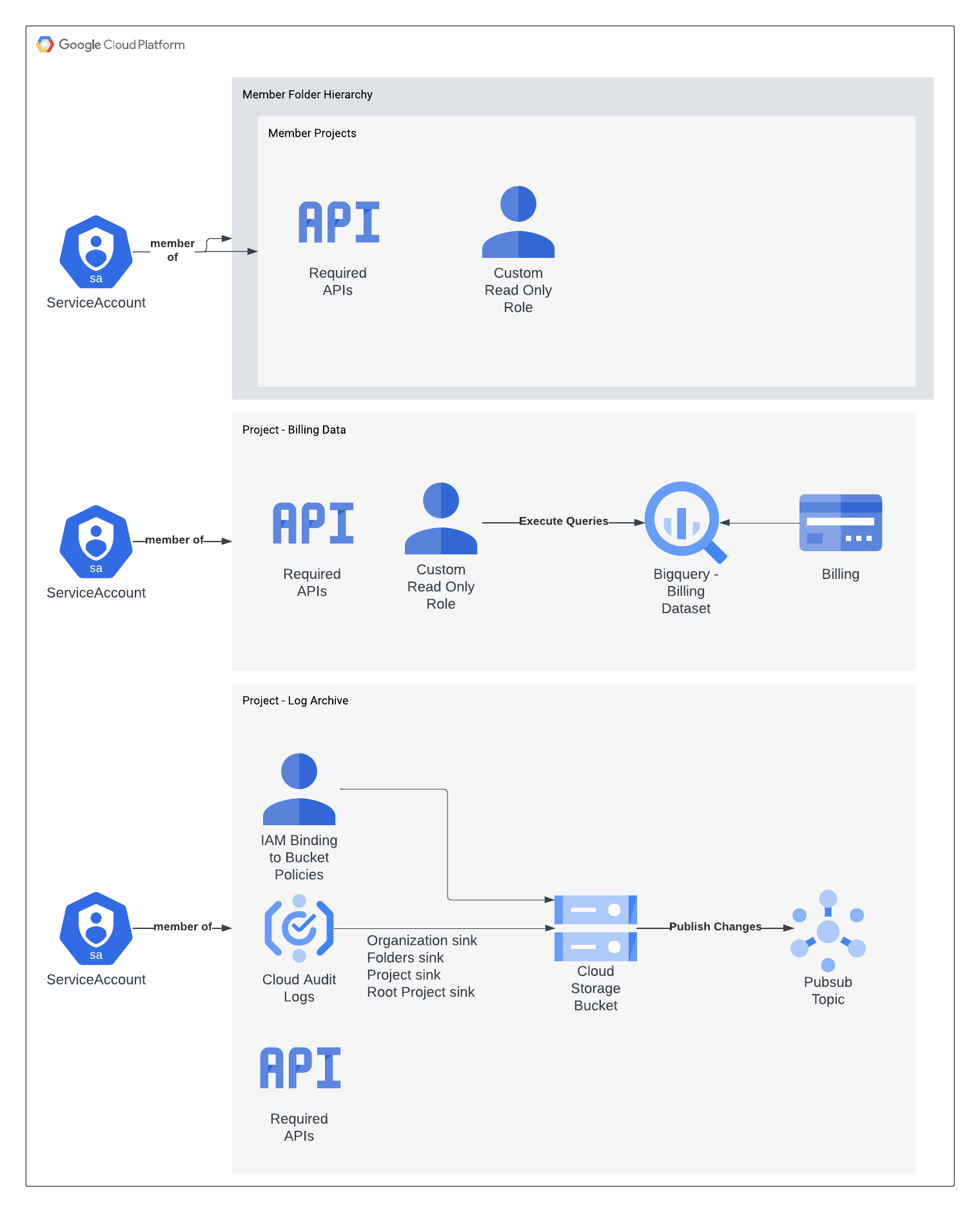
Architecture
Cloud ex Machina leverages a three-layer stack described on the below diagram:
Vocabulary and preliminary notions
The following definitions apply to the rest of this document:
- Management Project: the management project of a GCP Organization refers to the first project that was used to set up the Google Cloud Organization.
- Billing Account: the billing account refers to the billing account set up in the GCP Organization
- Components: Cloud ex Machina is organized around 4 main components that must be connected to your cloud.
- Organization Crawler: tracks the hierarchy of the GCP Organization such as folders, subfolders and projects.
- Detailed Billing Report Crawler: tracks usage and cost of assets in the target cloud
- Cloud Audit Log Crawler: tracks activity in the cloud that modifies assets
- Asset Crawler: maintains an inventory of assets in the cloud and their correlations. While this component exists logically, it is actually technically combined with the Organization Crawler component.
Organization Crawler
The Organization Crawler aims at getting a clear understanding of your cloud structure.
It requires access permissions installed in the Management Project of the each GCP Organization you have under management.
- Service Account: Provides Read Only access across the entire organization
Detailed Billing Report Crawler
The Detailed Billing Report aims at getting an accurate understanding of your GCP bills.
It is installed in the billing account and project of each GCP Organization you have under management and composed of
- Service Account: authorizes reading files in the BigQuery Dataset that contains billing exports
Cloud Audit Log Crawler
The Cloud Audit Log Crawler helps understand historical and dynamic aspects of your cloud.
It is installed in the GCP Logging Project and contains
- Service Account: authorizes reading files in the log bucket that contains CloudTrail logs
- PubSub Rules: feedback loop to notify crawlers of the availability of new files
Setup
Pre-requisites
Required Software
You will need the following dependencies to initialize Cloud ex Machina:
- Terraform: Install any version above 1.5.0. If you migrated to OpenTofu, this is also supported.
- jq: Install any recent version
- Google Cloud CLI: Install any recent version
Deployment Configuration
make sure to collect the following information:
- Mandatory from your GCP Environment:
- organization_id: the ID of your GCP Organization (12 digits).
- integration_project_id: ID of the core organization project
- billing_project_id: ID of the billing project
- logging_project_id: ID of the log archive project
- Optional from your GCP Environment:
- existing_bucket_name: name of the cloud audit pre-existing bucket if any.
- existing_sink_name: name of the cloud audit pre-existing sink if any.
- existing_detailed_dataset_id: name of the detailled billing BQ dataset if any
In addition, assemble credentials to configure Terraform providers for your GCP Management Project, your Billing Project and your Log Archive Project.
Unpack Modules
Unzip the artifact that Cloud ex Machina provided to you that contains all modules. Create a directory to host the configuration information with:
export CXM_ROOT="/path/to/cxm/root_folder"
mkdir -p ${CXM_ROOT}/modules ${CXM_ROOT}/config/gcp
mv cxm-artifact.zip ${CXM_ROOT}/modules
pushd ${CXM_ROOT}/modules
unzip cxm-artifact.zip && rm -f cxm-artifact.zip
popd
pushd ${CXM_ROOT}/config/gcp
Configure Terraform / OpenTofu
Prepare a new Terraform configuration file main.tf that contains the following sections :
State Backend
Configure this the way you usually do it.
Providers
# Provider for the GCP Organization Management Account
provider "google" {}
# This alias is to deploy the Billing component
provider "google" {
project = "billing-123456"
alias = "billing"
}
# This alias is to deploy the Audit Log component
provider "google" {
project = "logging-li123-jc456"
alias = "logging"
}
Local Variables
The local variables block uses the information you collected earlier
locals {
organization_id = "123456789123"
integration_project_id = "cs-host-5674sf654g6w"
billing_project_id = "billing-123456"
logging_project_id = "logging-li123-jc456"
}
Module Configuration
# Enable the organization
module "enable_organization" {
source = "../../modules/terraform-gcp-enablement"
providers = {
google = google
}
org_integration = true
organization_id = local.organization_id
project_id = local.integration_project_id
use_existing_service_account = false
service_account_name = "cxm-organization-crawler"
}
# Enable access to audit logs
module "enable_audit_logs" {
source = "../../modules/terraform-gcp-audit-log"
providers = {
google = google.logging
}
org_integration = true
organization_id = local.organization_id
project_id = local.logging_project_id
service_account_name = "cxm-audit-log-reader"
# existing_bucket_name = "cxmlabs-logging"
# existing_sink_name = "_Required"
aws_notification_endpoint = "http://aws.amazon.com"
}
# Enable access to GCP Detailed Billing
module "enable_billing" {
source = "../../modules/terraform-gcp-billing"
providers = {
google = google.billing
}
project_id = local.billing_project_id
service_account_name = "cxm-billing-reader"
# existing_detailed_dataset_id = "cxm-billing-dataset"
billing_dataset_location = "EU"
}
Deploy
Run
terraform init
terraform plan
terraform apply
and wait for the system to converge. Depending on the size of your estate, this can take from a few minutes to a few tens of minutes.
Share results
The deployment will output 3 JSON documents containing service account definitions to use by Cloud ex Machina. Kindly share this back to enable the configuration of your solution.